A Paradigm Shift to Data as the Core Product
In the journey toward refining our product, one significant hurdle was the ambitious scope of functionality testing conducted in parallel, which led to complexities in communication and managing expectations. Through collaborative efforts with the business teams, we addressed a multifaceted challenge, streamlining the advertisement administration process to enhance both accuracy and efficiency. The culmination of these endeavors led to the emergence of a distinct and innovative product from the Inspira Group‘s Data Science team: a comprehensive text processing infrastructure.
This architectural overview and detailed description of the infrastructure’s components were contributed by Borko Rastovic, Inspira Group Senior Data Engineer.
This infrastructure is a complex network of services set up in detailed, flexible pipelines. Each step is closely connected, meaning what happens in one phase affects the next, and all information is carefully put together with the outcome. The system can handle many different types of inputs, like documents, HTML, and images, showing its wide-ranging use and thorough approach.
Architectural Overview
The infrastructure’s architecture is underpinned by three fundamental components, each serving a critical role in the processing ecosystem:
- Extraction, Processing, and Storage Services: These services form the backbone of the system, easing the selection of documents for processing and the extraction of text from various formats such as documents, images, and HTML.
- Basic Text Processing Service (NLP): This part is equipped with an array of over ten tools, including functionalities for language detection, diacritization, transliteration, normalization, anonymization, sentence splitting, lemmatization, vectorization any many more. These tools are indispensable across all our pipelines, supplying the necessary foundation for advanced text analysis and processing.
- LLM Processing Service (LLM Module): Acting as a wrapper for the OpenAI API (or any alternative LLM platform), this module is designed for efficiency and scalability. It offers one prompt per endpoint, integrating seamlessly with the NLP service to enhance functionality. This part is crucial for monitoring costs effectively per endpoint and ensuring the reliability and accuracy of output validation.
Bonus: Introducing the Prompt Batch Tester – A Catalyst for Development
Amidst the development of the Job Formatter, a pivotal tool appeared to address a critical need within our development teams—the “Prompt Batch Tester.” This tool was conceived to empower product development teams, enabling them to efficiently test prompts on larger datasets. This capability is crucial for the refinement and optimization of AI-driven features and functionalities across our product suite.
Key Features of the Prompt Batch Tester
- Prompt Customization: Product managers can craft and define specific prompts, select the right model, and configure its parameters to best suit their project needs.
- Dataset Upload: The tool supports the upload of extensive datasets, easing a robust testing environment that closely mimics real-world application scenarios.
- Test on a large scale: By simulating how a prompt will perform in a larger scale of data, the tool offers valuable insights into its practical application and utility.
- Cost Forecasting: An essential feature of the Prompt Batch Tester is its ability to project the total operational costs of deploying such a product in a live environment. This aids in strategic planning and budget allocation.
- Response Time Evaluation: Understanding the response time is critical for assessing the scalability and user experience of the product. This tool supplies precise metrics, helping teams to optimize performance and efficiency.
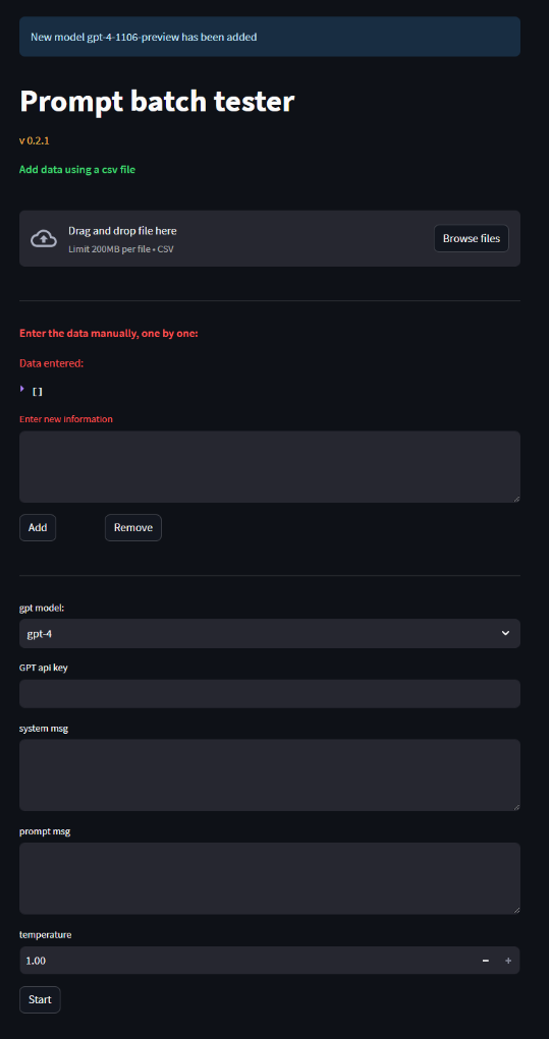
Figure 1 – “Prompt batch tester” user interface
Conclusion
Our innovative journey at Inspira Group has led us from the first prototypes to a robust AI-driven text processing infrastructure, revolutionizing the efficiency and accuracy of job ad moderation. Through the development of advanced tools like the “Prompt Batch Tester,” we have embraced challenges, iterated solutions, and unlocked new potential.
In collaboration with the Infostud team, we’ve also achieved significant milestones beyond job and moderation. Our development of an AI-powered CV parser has simplified the process for job seekers to craft distinctive profiles on our platforms. Moreover, we’re demystifying the interview preparation process with an innovative AI tool, making daunting tasks more manageable and less stressful for candidates.
As we look ahead, we are excited to collaborate with forward-thinkers and innovators. Together, let’s continue to break new ground and redefine what is possible in the evolving landscape of technology and work.
Author
Srđan Mijušković, Senior Product Manager at Inspira Group

